Сбор информации в целях выявления связи генотипа с фенотипическими особенностями предусматривает два ключевых подхода – opt-in и opt-out. В первом случае ведется активный рекрутинг участников исследований, которые сдают био-образцы, подписывая специальное письмо-согласие и одновременно предоставляя информацию о своих медико-демографических и других характеристиках.
Подход opt-out предусматривает то, что массив данных заимствуется из медицинских учреждений, в которых заведомо хранятся био-материалы от пациентов, к которым «привязана» медико-демографическая информация. Важным условием является полная де-идентификация пациентов, что позволяет соблюдать конфиденциальность. Данный подход является на сегодняшний день наиболее распространенным, однако он требует соблюдения важных условий конфиденциальности и этических требований.
Основными этапами создания генетического биобанка являются следующие:
Разработка программ подготовки и обработки био-образцов
Разработка синтетических дериватов (баз медико-демографических данных без персонифицированной информации)
Внедрение и валидация методологии де-идентификации
Проведение анализа по вопросам этики и работа над рекомендациями:
- Постоянный контроль со стороны Институционального этического комитета (IRB);
- Обеспечение условия, по которому все пациенты должны получать информацию о проекте, а также могут реализовать свое право отказаться от участия в сборе информации;
- Разработка плана комплексного обучения персонала, задействованного в сборе био-материалов и медико-демографических данных;
- Проведение мониторинга и текущей внешней оценки
Оценка содержания и функциональности базы данных перед регистрацией участников
Создание Консультативного совета по вопросам этики, а также Научно-консультативного совета
Организация клинических и юридических процессов
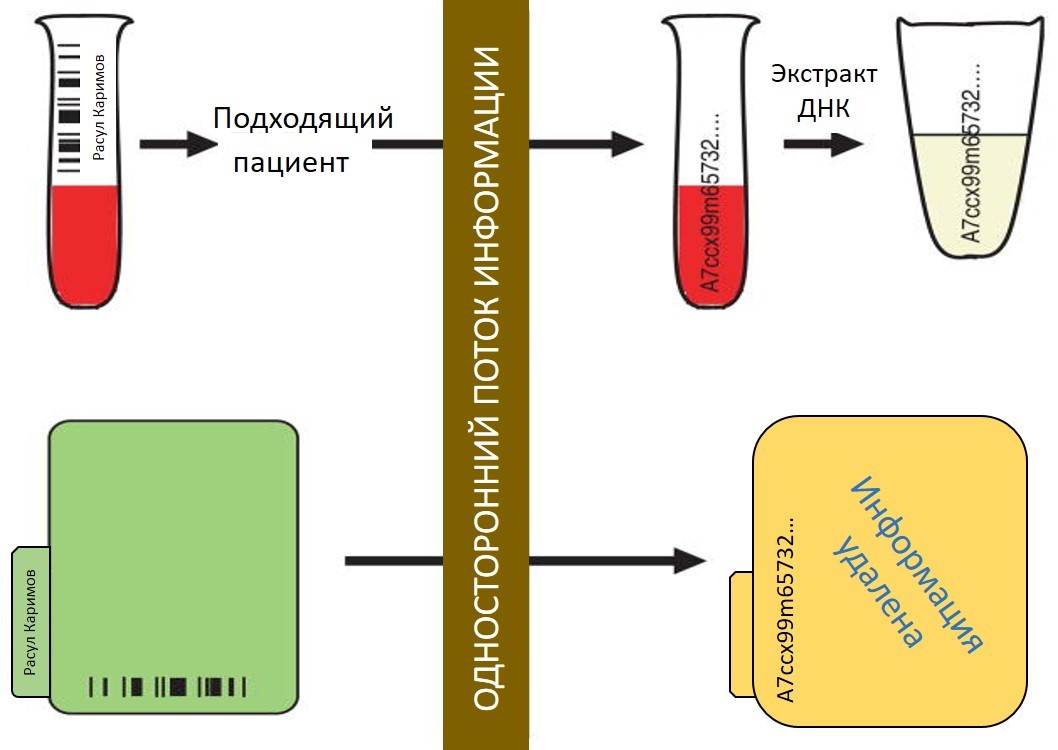
Основные компоненты создания биобанка по принципу opt-out является де-идентификация образцов крови пациентов и создание «зеркальной» информационной базы, в которой отсутствует персональная информация о пациенте. Такая база называется «синтетическим деривативом» — она должна гарантировать прерывание любой связи биологического образца (например, образца крови) с информацией, которая позволила бы идентифицировать пациента, которому принадлежит данный образец
С этой целью личную информацию о пациенте заменяют на зашифрованный код из приблизительно 30 цифр и букв (Уникальный Идентификатор). Обычно такой код генерируется рандомизированно, для чего применяется специальная программа. Не менее важным является то, чтобы не создавалось возможности восстановления персональных данных из какого-либо Уникального Идентификатора. Данный процесс в схематичном виде представлен на рисунке внизу.